
阅读笔记:Crowd-sensing Enhanced Parking Patrol using Sharing Bikes Trajectories
一、基本信息
- 阅读人和日期:BW Lin,2022.4.21
- 引用格式:He, T., Bao, J., Li, Y., He, H., & Zheng, Y. (2021). Crowd-sensing Enhanced Parking Patrol using Sharing Bikes Trajectories. IEEE Transactions on Knowledge and Data Engineering.
- 单位:Harbin Institute of Technology.
- 原文链接: https://ieeexplore.ieee.org/document/9662971
- 概述:摩拜单车庞大而高质量的共享单车轨迹为我们提供了一个独特的机会来设计一种无处不在的非法停车检测方法,因为大多数非法停车事件发生在路边,并对自行车使用者产生重大影响。检测结果有助于改善巡逻进度,进一步提高巡逻效率。检测方法采用三个主要组成部分:1)轨迹预处理,过滤异常值GPS点,执行地图匹配并建立轨迹索引;2)非法停车检测,对正常轨迹进行建模,从评估轨迹中提取特征,并利用基于分布测试的方法发现非法停车事件;3)巡检调度,利用检测结果,将调度任务建模为多智能体强化学习问题,指导巡警。通过大量实验验证了违章停车检测的有效性和巡逻效率的提高。
二、动机及创新点
动机:
非法停车事件通常发生在路边,阻碍了自行车使用者的道路,这严重影响了他们的行驶轨迹。因此,通过在同一条道路上的大量的自行车轨迹,检查其轨迹的不同模式来识别非法停车事件。本文使用大量共享单车轨迹,设计了一种有效的非法停车的检测方法。检测结果可指导巡逻调度,即派巡逻警察到非法停车风险较高的地区,进一步提高巡逻效率。
主要贡献及创新点:
- 首次尝试通过挖掘大量的自行车轨迹来广泛地检测非法停车事件。
- 提出了一种新的基于分布测试的检测方法来检测非法停车事件,并将该算法部署到分布式系统上,以提高停车效率。
- 第一个由被动众感(passive crowdsensing)检测结果驱动的非法停车巡逻框架。
三、问题描述和方法论
1. 问题描述
非法停车是世界上众多城市面临的一个常见问题,会导致交通堵塞,进而引发空气污染和交通事故。人类的主动检测非法停车事件对覆盖一个大城市是极其无效的,因为警察必须在整个城市的道路上巡逻(没有针对性,太耗费人力物力),因此急需一个方法来解决这个问题。
2. 轨迹预处理
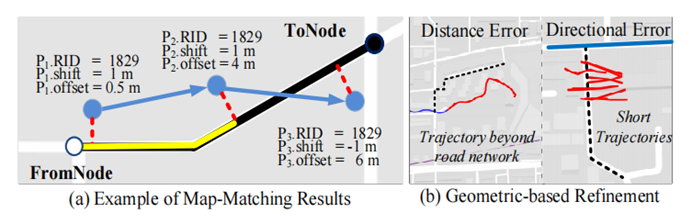
GPS轨迹可能不准且存在脏数据,因此要做数据清洗、地图匹配。地图匹配后每个GPS点都有三个属性:RID(匹配的路段id),shift(红色虚线部分,GPS点与匹配路段的最短距离),offset(黄色部分,GPS投影点与起始点的距离),如图所示为轨迹图:
3. 非法停车检测
1).基本思想
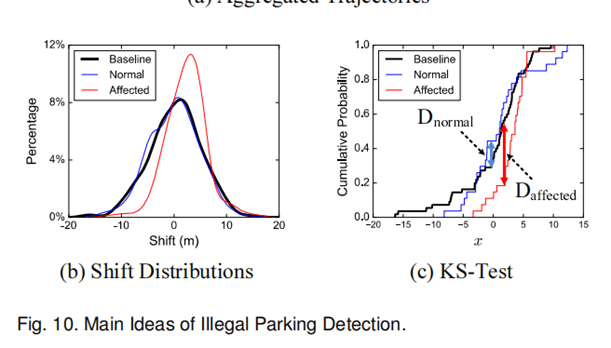
将聚合轨迹的shift分布作为特征来评估路段上是否存在非法停车事件。
为了计算聚集的正常轨迹(或基线轨迹)与同一路段的待评估轨迹之间的shift分布之差,进行了KS检验。
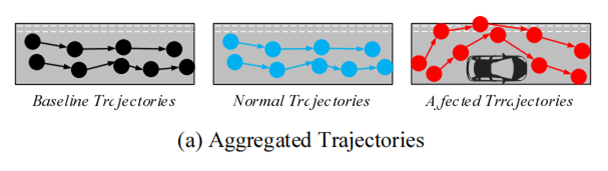
如果在评估轨迹上没有非法停车事件,则shift分布更相似。然后通过设置一个阈值来确定两组轨迹是否来自相同的分布,以此来推断是否存在非法停车事件。之所以使用阈值来判断,是因为非法停车事件造成的轨迹转移的影响在整个城市中是相同的(大约是车辆的宽度)。最后,可以通过评估不同阈值的测试结果确定最有效的阈值。
2).基于测试的分布检测
KS统计量的计算,本质上是计算两个经验累积分布函数之间的最大偏差:
$$
D_{n,m}={\rm SUP_x}\left|F_{1,n}\left(x\right)\ -\ F_{2,m}\left(x\right)\right|
$$
阈值的选择:
$$
D_{n,m}>c(\alpha)\sqrt{\frac{n+n}{nm}}\ and \ c(\alpha)=\sqrt{-\frac{1}{2}ln{\frac{a}{2}}}
$$
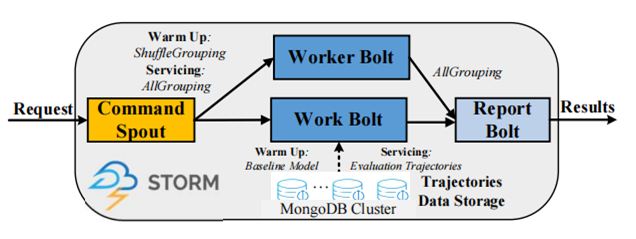
4. 检测系统的部署(具体实现)
该系统部署了一个基于并行计算的平台以提高基于整个城市海量轨迹的非法停车事件检测的响应时间。
5. 巡逻调度框架
对于政府来说,巡逻调度的安排可以被视为一系列的行动,为了优化巡逻调度的长期有效性,以解决非法停车动态问题,本文将巡逻任务制定为一个马尔可夫决策过程(MDP),并通过多智能体强化学习(MARL)来解决巡逻任务调度。
1).普通的Q-learning
给定一个MDP,它学习评估状态-行动组合的最大长期累积折扣奖励,即Qvalue函数,形式为:
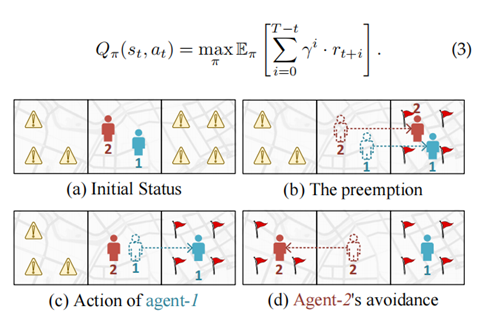
Q值估计的公式:
$$
Q\left(S_t,a_t\right)=\gamma_t+\gamma\cdot{max}\ Q\left(S_{t+1},a\right)
$$
由于由于状态空间S和动作空间A非常大,可通过DQN来学习Q函数(本质为最小化下面的函数):
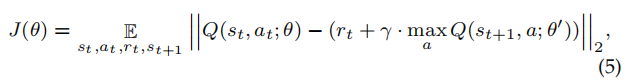
2).多智能体强化学习
假设有多辆巡逻车(N辆),那么动作空间会很大。为了解决这个问题,将N辆巡逻车视为共享共同模型并独立行动的同质代理,即代理基于共同共享的政策采取行动,并最大化自己的总回报。论文设置了一个代理的优先级方案,逐个评估和生成每个代理的行动,而不是同时生成所有代理的动作。
具体算法为:

文中城市的非法停车环境是通过模拟来实现的。具体算法为:
