阅读笔记:Multi-Task-Oriented Vehicular Crowdsensing:A Deep Learning Approach
一、基本信息
- 阅读人和日期:WN Zheng,2022.5.3
- 引用格式:Liu, C. H., Dai, Z., Yang, H., & Tang, J. (2020, July). Multi-task-oriented vehicular crowdsensing: A deep learning approach. In IEEE INFOCOM 2020-IEEE Conference on Computer Communications (pp. 1123-1132). IEEE.
- 单位:Beijing Institute of Technology,UC Berkeley.
- 原文链接:https://ieeexplore.ieee.org/abstract/document/9155393/
- 概述:本文提出了一种基于深度强化学习(DRL)的集中控制、分布式执行框架,用于面向多任务的VCS,称其为DRL-MTVCS。它包括一个具有时空状态信息建模的异步架构,通过自适应归一化的面向多任务的值估计,以及像素控制的辅助车辆动作探测。与三个基础实验进行了比较,结果表明,当不同的任务数量、车辆、充电站和传感范围发生变化时,DRL-MTVCS在能源效率方面优于其他所有方法。
二、动机及创新点
动机:
车辆群智感知(VCS)利用无人车,包括无人机和无人驾驶汽车,这些车辆通常配备了高精度的传感器,与智能手机相比,能够在更大范围内收集数据。为了长期使用,它们还配备了自动充电、自动返航机制。在某些情况下,4G/LTE网络可能暂时不可用,本文使用一组无人驾驶车辆,这些车辆通过控制逻辑导航,在每个传感场景中移动,以便从PoI收集数据,初始能量储备有限,充电站分散和障碍物。由于这些类型的突发事件无法事先准备好,因此需要一个通用的控制逻辑,适合所有性质相似但设置不同的任务,如PoI/obstable分布。此外,本文的目标是最大限度地提高数据收集和地理公平性,同时最大限度地减少所有任务的能耗,其中车辆不应在途中撞到任何障碍物或耗尽能源。
主要贡献及创新点:
- 本文提出了一个新的深度学习框架,称为DRL-MTVCS,用于面向多任务的VCS。它只用一个DRL代理和一组参数就能解决大量感知任务。
- 本文使用深度卷积ResNet,然后使用LSTM递归层来加强在多个任务中提取时空状态特征的能力。本文还通过结合解耦作用和学习架构,在高吞吐量(分布式执行)下实现稳定的学习。
- 本文通过增加两种技术来改进IMPALA。(a)通过自适应归一化进行面向多任务的值估计,(b)通过像素控制进行辅助车辆行动探索,专门用于本文的多任务VCS问题。
- 本文进行了广泛的模拟,并与三个基础实验进行了比较。结果表明,本文的模型是有效的,并且具有更好的性能。
三、问题描述和方法论
(1)当任务i∈N完成时,计算导航策略π下所有车辆的数据采集率:
$$
D _ { i } ( \pi ) = \frac { \sum _ { p E _ { i } } \phi _ { i } ( \pi ; p ) } { \sum _ { p e } d _ { i } ( p ) } , \forall i \in N.
$$
(2)任务i中收集到的数据的地理公平性可以用公平性指数表示为一个度量:
$$ w_{i}(\pi)= \frac{(\sum _{p \in P_{i}}\phi _{i}(\pi ;p))^{2}}{P_{i}\sum _{p \in P_{i}}\phi _{i}(\pi ;p)^{2}}, \forall i \in N. $$(3)定义车辆u对任务i的能耗模型为:
$$
e_{i,t}^{u}(\pi)= \alpha \cdot d_{i,t}^{u}(\pi ;p)+k \cdot a_{i,t}^{u}(\pi), \forall u \in \mathcal{U},i \in \mathcal{N},t,
$$
(4)解决方案的概述
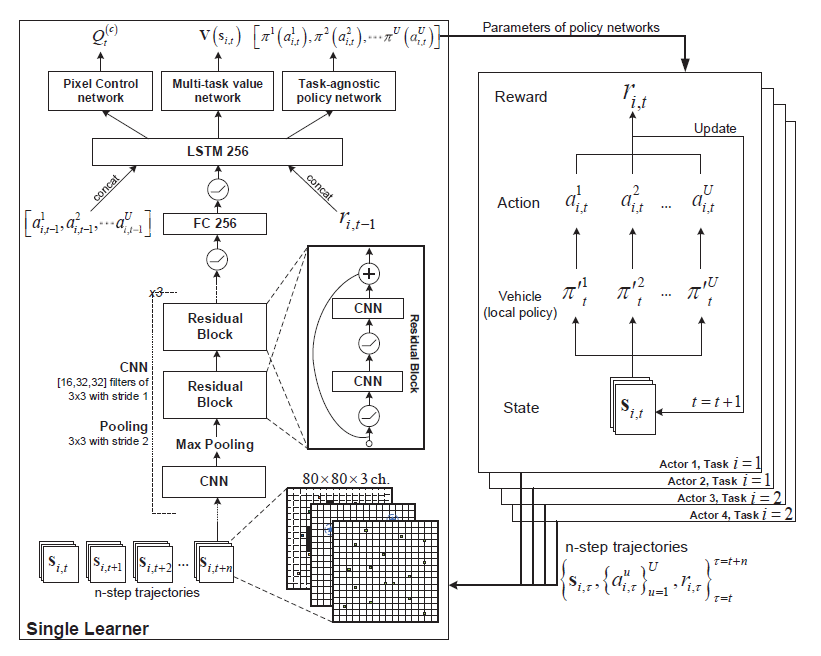
四、算法设计
本文的算法主要分为两部分:多个CPU Actors和一个GPU Learner。行动者执行不同任务i∈N的所有行动,为每个车辆u评估参数为η’的本地策略,并定期和异步地将经历的轨迹发送给学习者。
(1)actor

(2)Learner

五、实验部分
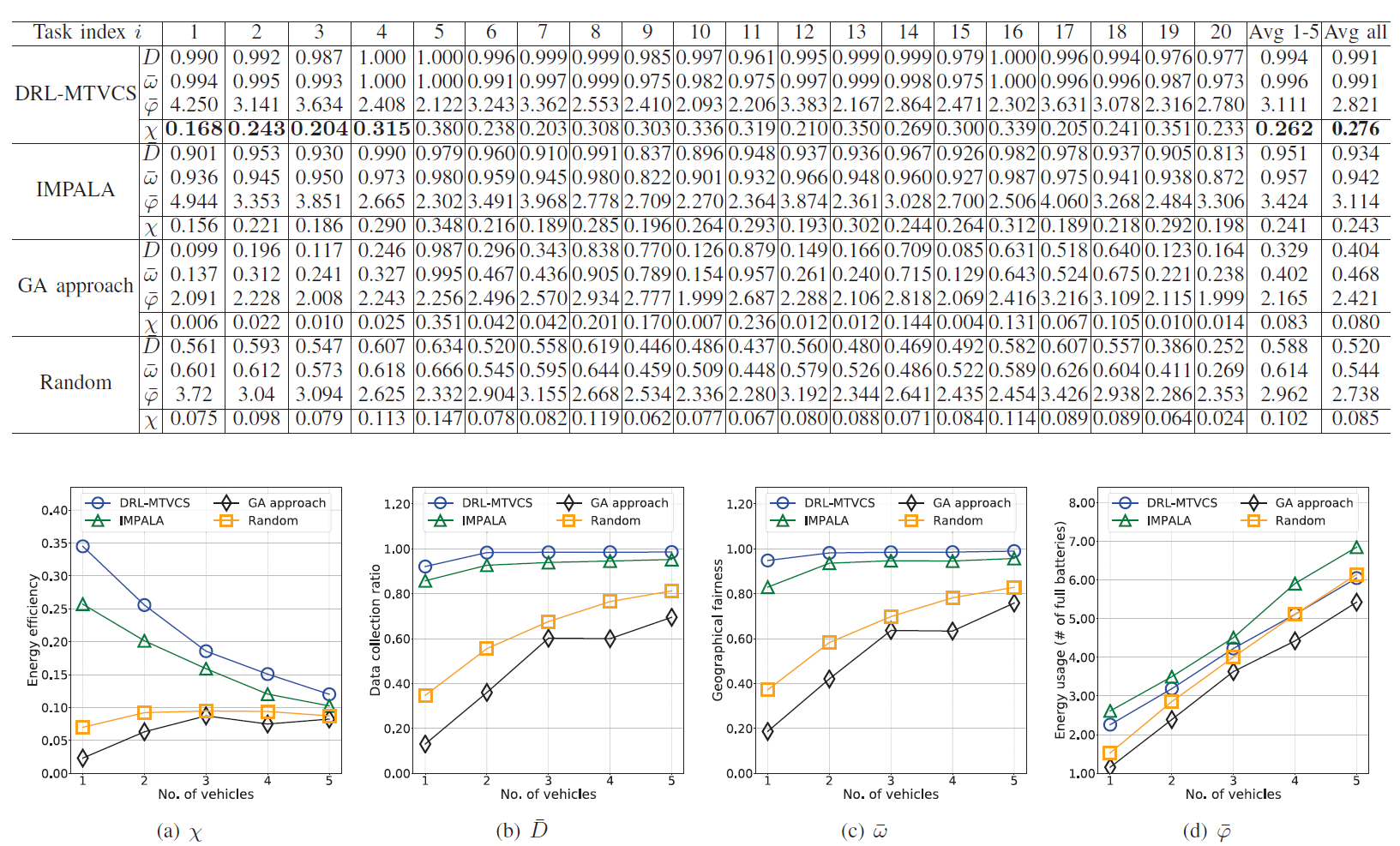
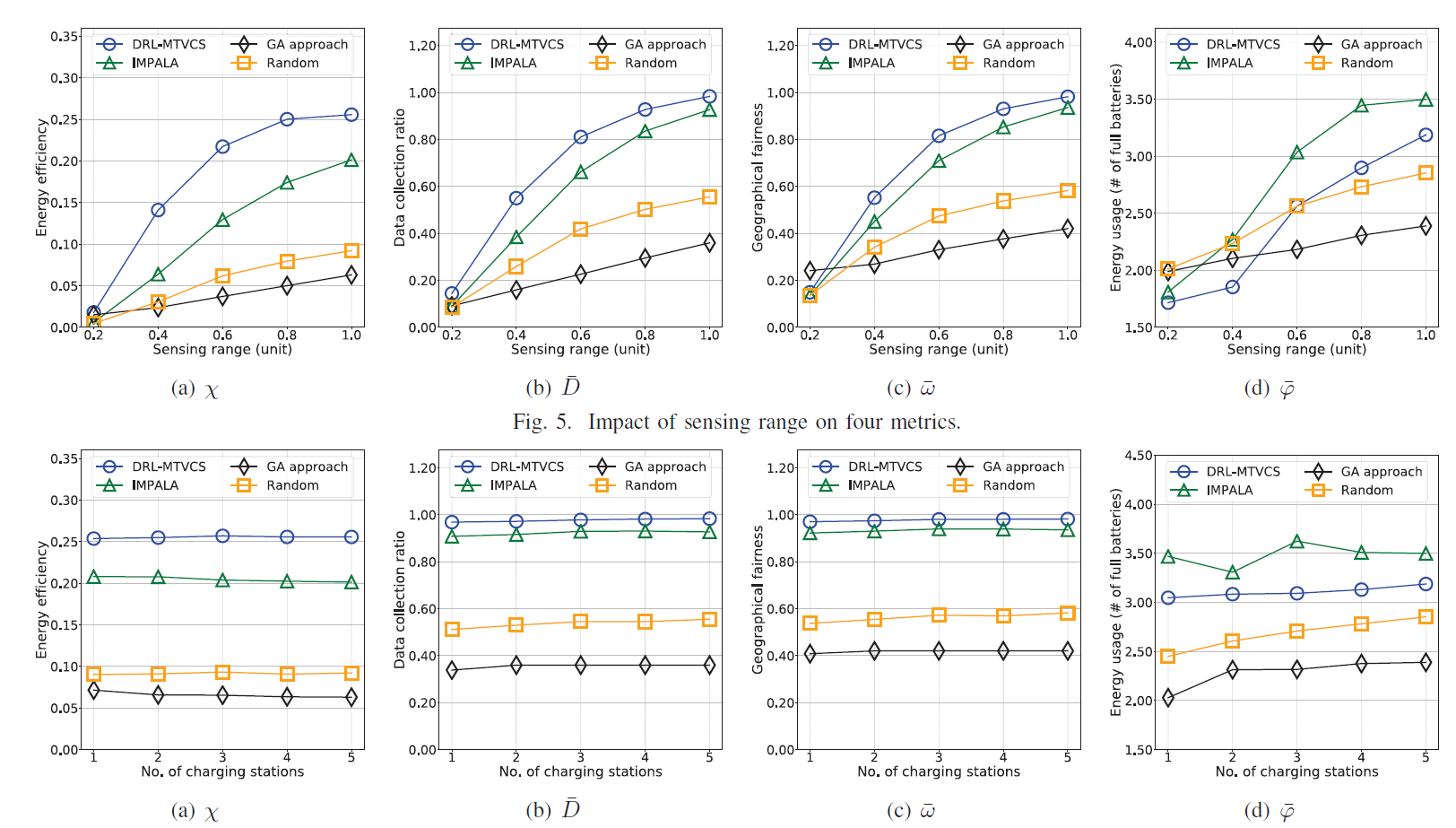
(1)本文采用仿真实验,实验设置为:将每个任务的目标区域设定为一个二维正方形,大小为8*8个网格,其中50-300个PoIs均匀分布。设计了20个任务。我们在(0,1)范围内随机初始化了每个PoI的相关数据量。每辆车开始时有40个单位的能量储备(作为一个完整的电池)。在我们的实现中,我们设置了α=0.1和κ=1,也就是说,对于收集一个单位的数据和一个单位距离的车辆移动之间的能量成本,比例为α:κ=1:10。 障碍物碰撞的惩罚ρu t=1.0。然后,我们将每辆车在一个时间段内可以从PoI s数据中收集的比例设定为20%。行动空间包含25个相邻的网格,一辆车可以在附近选择。.
(2)实验结果:在像素控制的辅助探测机制的帮助下,本文保证了动作探测的持久性和强度,DRL-MTVCS仍然可以达到92%的数据采集率和95%的地理公平性,比图4(b)和图4(c)中的基线有很大的增益。