
阅读笔记:RL-Recruiter+: Mobility-Predictability-Aware Participant Selection Learning for From-Scratch Mobile Crowdsensing
一、基本信息
- 阅读人和日期:WJ Huang,2022.5.27
- 引用格式:Hu, Yunfan, et al. “RL-Recruiter+: Mobility-Predictability-Aware Participant Selection Learning for From-Scratch Mobile Crowdsensing.” IEEE Transactions on Mobile Computing (2021)..
- 单位: Santa Clara University.
- 原文链接:https://ieeexplore.ieee.org/abstract/document/9424406
- 概述:利用少量的历史轨迹计算参与者移动模式的可预测性,通过强化学习框架迭代地选择感知覆盖率更高且移动模式更稳定的参与者。
二、动机及解决方法
动机:
之前的MCS在选择工人时,都是基于大量的历史轨迹,这是不现实的,该论文就研究了如何智能地选择参与者,以最小化这种“冷启动”效应。随着时间的推移,流动轨迹逐渐累积,RL-Recruiter+能够为每个感知时段做出一系列良好的参与者选择决策。
解决方法:
构建一个强化学习框架RL-Recruiter+,在每个连续的感知时隙中选择一组合适的工人,在任务执行之前,RL-Recruiter+首先根据之前的感知时间段中的信息,计算两个值函数,通过值函数迭代的选择一组合适的工人,并且将这组工人参与行动的轨迹加入历史轨迹中继续训练。
三、方法论
1.RL框架的构建:
框架图:
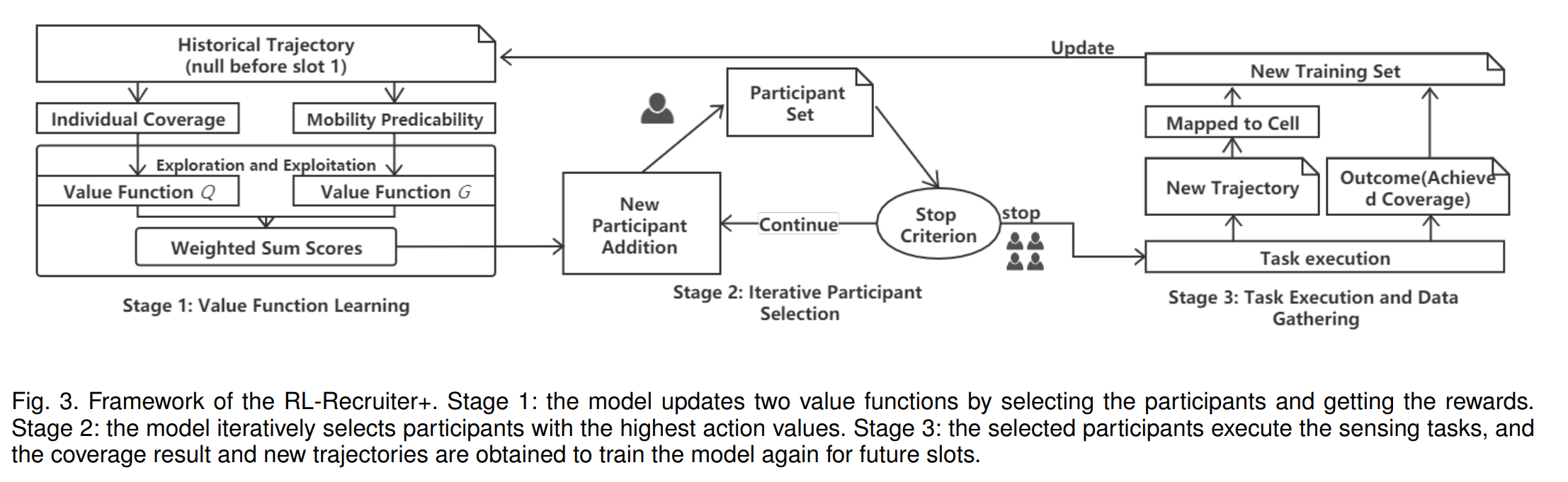
第一阶段:模型通过选择参与者并获得奖励来更新两个价值函数。
第二阶段:模型迭代选择行动价值(两个价值函数的加权和)最高的参与者。
第三阶段:选定的参与者执行感知任务,获得覆盖结果和新的轨迹,再次训练模型。(有反馈)
将参与者的流动性可预测性引入到学习过程中
倾向于选择那些在之前的时段中覆盖率较高的人,而且更喜欢那些流动模式相对稳定的人
2.RL状态与动作设置
状态:假设有z个工人,在选择第k个工人,则把第k维中的值将0置为1(没选就是0)
状态由s->s’
动作:选择一个动作时,它实际上会选择一个与所选动作对应的参与者。此外,RL Recruiter+不会通过检查当前状态s来选择之前已经选择的参与者。如果状态s的第k维设置为1,则行动ak不可用,RL Recruiter+将不会执行该操作。
奖励:在采取行动后,RL Recrupter+将从历史轨迹数据中获得奖励。将奖励设置为在工人集合P中加入工人后增加的区域覆盖率。
3.系统详细构成
第一阶段,值函数学习:

第二阶段:迭代选择工人
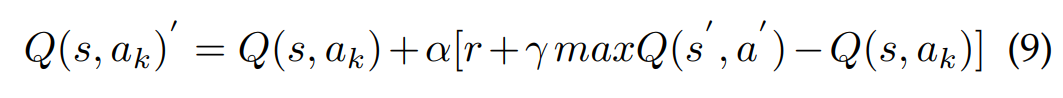
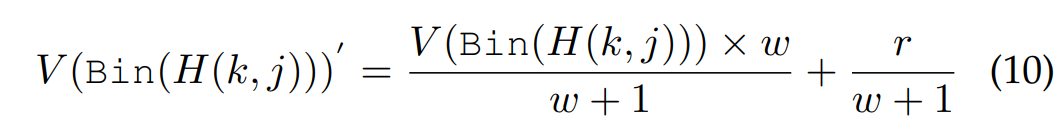
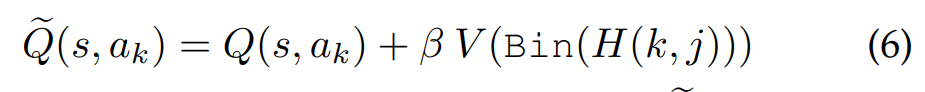
通过式9和10,选择一个新的工人集,迭代的选择具有式6中价值最高的工人
论文最后提到 :“尽管评估清楚地表明 RL-Recruiter+ 更有效,但我们并不声称该方法本身可以推广到参与者选择问题的所有变体”。